머신러닝으로 '음역' 해보기
개요
회사에서 기계 학습과 관련된 프로젝트는 거의 다 맡으려고 하고 있다. 다만 내 본래 역할은 인프라 엔지니어인 탓에 (...) 많은 시간을 할애하지는 못하고 있다. 이번에 하게된 프로젝트는 음역 (Transliteration) 을 기계학습을 통해 자동화 시키는 작업이었다. 한글 언어 모델을 학습시키려고 하는데, 영어 단어가 너무 많이 포함되어 별도의 표준화 작업이 필요하다는 이유에서 였다.
데이터는 사내의 데이터 담당 분들이 (손수) 모아주셨다. 각종 발음 관련 사이트와 영어 단어를 모으고 "직접" 기입하는 식으로.. 그렇게 15만개 가량의 단어셋으로 학습을 진행하게 되었다.
데이터를 가공하는 것과 모델을 튜닝해가면서 겪었던 경험들을 최대한 풍부하게 써보려고 했다.
(질문은 Github Issue 로...)
데이터 가공

우선 데이터는 매우 간단했다. 영어 단어와 발음 밖에 없다.
하지만 크롤링으로 가져온 탓인지, 중간중간 특수기호(?,-,*,&) 가 보였다.
우선 순수한 영어 알파벳을 가지고 음역하는 것이 목표였으므로, 정규식을 이용해 영어와 한글이 아닌 문자는 모두 제거했다.
입출력 정의
데이터 다음으로 가장 중요하다고 생각하는 부분이다. 입출력을 어떻게 잡느냐에 따라서 정확도가 크게 달라진다.
한글 데이터의 경우, 조합형 문자이므로 여러 출력 방식을 사용할 수 있다. 그 중 두 가지의 방식을 실험해보았다.
- 이미 조합된 글자 자체를 출력
> 조합 가능한 모든 글자를 벡터에 추가
> 데이터셋에 나온 글자만 벡터에 추가
- 자/모 음을 출력하고, 조합
다만 여기서 "조합 가능한 모든 글자를 벡터에 추가" 하는 방식은 너무나 낮은 정확도를 보였으므로,
(경우의 수가 너무 많아 벡터가 sparse 해지는 문제점이 있다. 테스트 해보나 마나..) 여기선 생략한다.
GRU2GRU_letter
모델 코드: https://github.com/Kcrong/English2Korean/blob/master/GRU2GRU_letter.py
데이터셋에 나온 글자만을 이용해, 출력을 정의하고 GRU 모델을 이용해 Seq2Seq 모델을 만들었다.

기본적인 알파벳 임베딩을 위해 케라스의 Embedding Layer를 사용했고, Encoder/Decoder 부분에서 중첩 GRU Layer 를 사용했다.
Decode 후에는 classification 결과값을 위해 TimeDistributed Dense Layer와 Softmax 를 사용했다.

당연하게도, 과적합 현상이 발생했다. 학습데이터에서는 100%에 가까운 정확도를 보이는 반면, validation set에 대한 정확도는 82% 밖에 나오지 않았다.
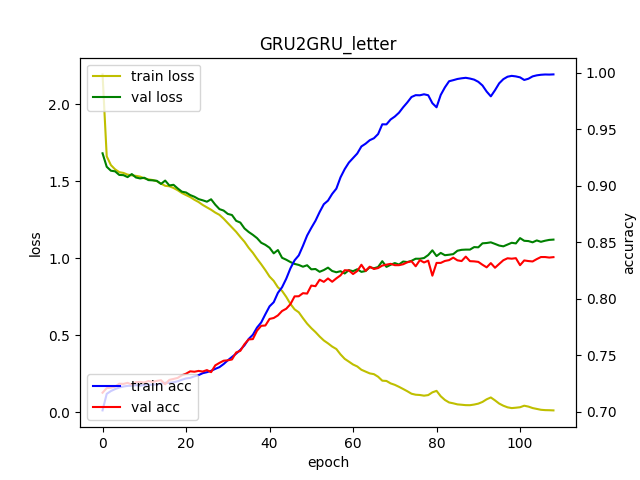
전체 그래프에서도 train acc 와 val acc 가 많이 차이나는 모습을 볼 수 있다.
혹시나 하는 마음에 딥러닝의 대가, Andrew Ng 선생님의 말씀을 따라 Dropout을 사용해 보았다.
GRU2GRU_letter_dropout

출력 벡터가 너무 제한적이어서 디코딩에서 오버피팅이 났을거라 생각하여 Decoder 부분에 각 GRU 부분 마다 Dropout을 추가했다.

데이터셋이 적을 때는 train set에 대한 정확도는 조금 떨어지는 대신 validation set에 대한 값은 조금 더 올라갔다. dropout 레이어 덕에 그래프도 요동치는 것이 줄고, 조금 더 완만한 모양을 그렸다.

다만 조금 더 큰 데이터를 이용해 학습시켜본 결과, 정확도는 오히려 떨어졌다.
RNN에서 Dropout을 이용한 사례가 있는지 검색을 해봤더니, 아래와 같은 정보를 찾을 수 있었다.
Unfortunately, dropout Srivastava (2013), the most powerful regularization method for feedforward neural networks, does not work well with RNNs.
The dropout operator corrupts the information carried by the units, forcing them to perform their intermediate computations more robustly. At the same time, we do not want to erase all the information from the units.
출처: Recurrent Neural Network Regularization (Wojciech Zaremba, Ilya Sutskever, Oriol Vinyals)
위 논문에 따르면, RNN에서의 Dropout은 과거의 정보까지 손상시키기 때문에 원활하게 동작하지 않는다고 한다.
모델 자체의 문제보다, 출력 설계에 대한 문제가 더 크다고 생각하여 출력을 바꾸어보기로 했다
GRU2GRU_consonant-vowel


기대했던 만큼 좋은 결과는 나오지 않았다. 기존의 글자 방식과 별반 차이가 없어보였다.
다만 등장하지 않는 글자도 내놓을 수 있고 무엇보다 자/모음과 알파벳의 상관관계를 학습시킬 수 있어 더 좋은 결과를 내놓을 수 있다고 확신했다.
LSTM2GRU_consonant-vowel_flip
추가 튜닝에 대한 답은 또 다른 논문에서 찾을 수 있었다.
While the LSTM is capable of solving problems with long term dependencies, we discovered that the LSTM learns much better when the source sentences are reversed (the target sentences are not reversed). By doing so, the LSTM’s test perplexity dropped from 5.8 to 4.7, and the test BLEU scores of its decoded translations increased from 25.9 to 30.6.
Sequence to Sequence Learning with Neural Networks (Ilya Sutskever, Oriol Vinyals, Quoc V. Le. 2014)
정리하면, LSTM에서 input을 뒤집으면 학습이 좀 더 원활하게 된다는 것이었다.
저 논문대로 Encoder 부분에 LSTM을 사용하고 numpy.flip 을 이용해 입력값을 뒤집어서 학습시켜 보았다.


예상외로 처음 모델과 큰 차이를 보여주었다. 똑같은 데이터셋에 Encoder 레이어와 Input 데이터를 뒤집어주었을 뿐인데, 정확도가 약 2% 증가했다.
알파벳과 자/모음 관계를 유지하고, Input을 뒤집어 Back Propagation 이 원활하게 진행된 결과라고 예상한다.
정리

'기계학습' 카테고리의 다른 글
| About recall, precision (0) | 2017.02.16 |
|---|---|
| 인공신경망 Neural Network #1 ( 구현 수정본) (0) | 2016.05.26 |
| 인공신경망 Neural Network #2 (0) | 2016.05.26 |
| 인공신경망 Neural Network #1 (1) | 2016.05.26 |
| 주요인사연설분석 자동화 (0) | 2016.04.15 |
